SuperVersion
SuperVersion是RocksDB用来优化LevelDB并发模型的技术。首先我会先回顾一下LevelDB的并发模型,然后再分析SuperVersion是如何对此进行优化的。
SuperVersion是RocksDB用来优化LevelDB并发模型的技术。首先我会先回顾一下LevelDB的并发模型,然后再分析SuperVersion是如何对此进行优化的。
Cuckoo Hashing是一种用”布谷鸟”的方法解决哈希冲突的算法,其最坏的查找时间是O(1)。
Cuckoo指的是“布谷鸟”,为什么是“布谷鸟”呢?因为有一种布谷鸟会把蛋生在别人的鸟巢里,然后把别人家的蛋推走。Cuckoo Hashing使用类似的方法来解决哈希冲突,如果在插入数据时发现冲突了,就将冲突位置上的数据搬走。
丹麦的两位教授在2001年首先发表论文阐述了该算法。paper
论文中一段代码阐述了算法的核心部分:
插入x时,如果找到就返回;否则进入循环,循环次数最大为MaxLoop。
在循环里,如果T1表中x的位置为空,插入x到T1表返回;否则,将x和当前位置上的指交换;
此时x变成被挤出来的值,尝试同样方法插入到T2;直到找到空余的位置。
如下图,x插入T1后,y被推到T2表,又导致了z从T2被推出来,直到z在T1找到了空的位置。
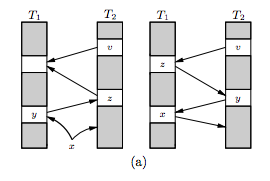 12345678910procedure insert(x) if lookup(x) then return loop MaxLoop times if T1[h1(x)] == null then { T1[h1(x)] = x; return} swap(x, T1[h1(x)]) if T2[h2(x)] == null then { T2[h2(x)] = x; return} swap(x, T2[h2(x)]) end loop rehash(); insert(x)end
12345678910procedure insert(x) if lookup(x) then return loop MaxLoop times if T1[h1(x)] == null then { T1[h1(x)] = x; return} swap(x, T1[h1(x)]) if T2[h2(x)] == null then { T2[h2(x)] = x; return} swap(x, T2[h2(x)]) end loop rehash(); insert(x)end
RocksDB把HashCuckoo用作Memtable的一个可选算法,其他算法还包括SkipList, HashLinkList, HashSkipList。只有HashCuckoo的最坏查找时间是O(1),在某些使用上有一定的优势。
下面分析Memtable主要的两个接口Get和Insert。
|
|
HashCuckoo使用了10个(hash_functioncount)哈希函数来解决冲突。
搜索key键值,依次遍历这个10个哈希函数,依次判断每一个哈希结果的位置是否为空;如果不为空,判断该位置键值是否与key相同,相同则返回;不同则继续下一次哈希。如果位置为空则退出循环,因为HashCuckoo的插入是从最低的哈希函数开始寻找位置的,如果空说明该键值不存在。退出循环在backup哈希表里进行查找。
|
|
插入流程相对查找流程较为复杂,前面的论文中以两个哈希函数来解决冲突,RocksDB使用10个哈希函数,所以插入时产生冲突了会出现树形结构的遍历,每个树节点都有10个子节点。FindCuckooPath函数就是使用BFS广度优先搜索在树形结构遍历中查找到空的位置,并记录下查找路径需要推出的位置cuckoopath。
FindCuckooPath的实现在下面进行分析。如果FindCuckooPath查找不到空的位置,就尝试在backup_table里面进行插入。如果FindCuckooPath返回true,后面就根据FindCuckooPath填充的cuckoopath依次将路径上的键值往后一个位置移动,最后插入新key。
|
|
QuickInsert快速的搜索key对应的10个哈希位置是否有位置可以插入。
如果没有查找到,那么就要开始使用BFS算法进行搜索。其中CuckooStep用来记录可以回退的步骤,stepbuffer则保存了BFS搜索的队列。1for (unsigned int hid = initial_hash_id; hid < hash_function_count_; ++hid)
将搜索key的10个哈希位置都入到队列,后面While循环进入BFS搜索,每次从队列头取出一个步骤,如果步骤的深度已经超过cuckoo_path_maxdepth返回。如果该位置的key和搜索的key相同,则出现了循环,跳过该次搜索。以上条件都不满足,将改步骤的其他哈希位置(由于cuckooHash总是从最低位的哈希函数开始插入,我们只需要从大于当前哈希的函数的位置开始搜索)入到队列。
一旦找到了一个空的哈希位置,从stepbuffer中回溯出搜索的路径存到cuckoo_path。
2016年在西安出差,周末起了沙尘暴,只能在酒店呆着,一时无聊至极。
想起之前在家里通过Raspberry Pi观看美剧的软件,心想为什么不自己做一个在线看美剧的网站呢?
在前些时间,在家里用Raspberry Pi鼓捣过一个家庭影音,其主要的功能是依托OSMC这款开源软件。热心的”jindaxia”制作了一个美剧插件,使得我们能够在电视机大屏幕上有非常好的美剧观影体验。
基于这款美剧插件的基本原理, 只花了半天时间,用js代码拼凑了一个非常简单的chrome插件。当天我把它Po到了v站上,收到了不少网友的反馈。尽管简单,但非常实用,甚至有人说这种极简风格非常喜欢。
但是,插件的上手曲线还是比较大,从而诱发了我做一个网站的设想。
直到今年6月了解到《权利的游戏》第七季马上回归了,我才开始着手实现一直以来的想法。
设计上有几点考虑
后端使用Express + Redis,由于网站逻辑简单,RESTFul的接口定的很简单。12345678910app.get('/api/search/:title', function(req, res) { var api = SERVER + '/v3plus/video/search' var body = {'title': req.params.title }; console.log('/api/search/'); // Check Redis and get from remote cacheAndGet(api, body, getJSON, function(json){ res.send(json); })});
前端使用React + Boostrap,基本上是第一次用React,没想到用起来这么方便易学。
使用React-Router做前端路由,再基于Velocity来做一些简单的动画效果。
有了架子,逐个逐个页面去开发,效率也非常高,开发的过程中去发现复用的代码来重构,降低复杂度。
基于组件式的开发,使页面更加模块化,可维护性非常高。123456789101112131415161718192021222324class SeasonList extends Component { constructor(props) { super(props); } render() { let seasonList = [] let objList = this.props.objList; for(var i = 0; i < objList.length; i++) { let obj = objList[i]; seasonList.push(<Season key={i} id={obj.id} cover={obj.cover} title={obj.title} intro={obj.intro} /> ); } return ( <div> { seasonList } </div> ) }}
整个网站的核心其实是在于视频源的获取,实际上网站是不存储任何的视频,所有源都来自于“人人视频”。而人人视频是没有网页版的,我觉得是处于当前大环境打击盗版的原因。
后端通过Mock移动端的接口,获取到视频的播放地址。不过要获取这个地址并不容易,首先要能够分析出接口的地址,再者要截取到接口的参数。
一般会有以下的方法:
“人人视频”的接口是RESTFul形式,我使用Fiddler抓包,已经能够把基本功能的接口都逆向出来了,比如“搜索”,“分类”,“剧集信息”等等。
最关键的视频源接口,在抓包发现了一个签名字段,而且字段每次都不一样,猜测和时间戳有关系,应该是通过摘要算法把时间戳和其他信息包含在内,在服务端会进行校验。这时就只能通过APK逆向来找到对应的算法。
使用cfr逆向出来的代码,可读性更高,很快就能找到了该签名的摘要算法1234567key = 'episodeSid=' + req.params.episodeSid;key += 'quality=' + 'super';key += 'clientType=' + FAKE_HEADERS['clientType'];key += 'clientVersion=' + FAKE_HEADERS['clientVersion'];key += 't=' + FAKE_HEADERS['t'];key += SECRET_KEY;headers['signature'] = md5(key);
网站上线以后发现初次加载性能太慢,调查过是因为React将所有组件打包到一个js文件,初次加载时间非常长。
优化方法是使用react-router的getComponent来实现按需加载的方法:12345678910111213141516171819202122function asyncComponent(getComponent) { return class AsyncComponent extends React.Component { static Component = null; state = { Component: AsyncComponent.Component }; componentWillMount() { if (!this.state.Component) { getComponent().then(({default: Component}) => { AsyncComponent.Component = Component this.setState({ Component }) }) } } render() { const { Component } = this.state if (Component) { return <Component {...this.props} /> } return null } }}
与此同时,在后端Express加一个压缩中间件,压缩率可达40%,初次加载时间缩短70%以上。
由于这个网站是业余项目,个人也不打算投入太多精力时间,使用Heroku虽然慢了点,不过免费这一点完胜。另外Heroku支持github的hook,完美的实现了我的Devops要求,每次写完一个feature,只要直接push到Github,什么都不用管,方便!直接!
前端代码里加了google-analytics,可以实时对网站的运行情况进行监控。
尝试在一些论坛、社交媒体上做过推广,效果不佳。后来在页面也加了社交分享功能,使用的人也不多。目前日均ip在1500左右,顺其自然好了。
现在的应用开发对于开发人员来说,简化了很多流程。脚手架很多,工具很多,Paas又减少了很多部署的难度,一个网站开发到上线只需2天。
将来编程开发上手的难度只会越来越低,一个产品重要的不在是程序员的能力,更多是产品经理的,运营的能力,程序员随时可替代。
当然只是初级的,想要不可替代,成为高级是唯一选择。
附上项目地址: Github 网站
2017年5月3日,19点44分,傲娇的杨杨出生于香港玛丽医院。
看看这傲娇的小眼神(照片摄于2017-05-31)

杨杨妈妈当天17点01分微信告诉我破水了,我从公司马不停蹄的赶到了医院,就在我走进产房10分钟后,杨杨就迫不及待的出来了。我在病床边握着妈妈的手,看着杨杨静静地趴在妈妈身上。那幼小的身躯颤颤地抖动,微微睁开一只眼睛,看见了这个世界第一个认识的人 ———— 就是我。不一会,姑娘弹了一下杨杨的小脚丫,他便开始放声大哭,“哇啊哇啊……”。强而有力的声音,正如爷爷对他的期待,要像一个小白杨一样坚韧不拔,屹立不倒。
就这样,角色变化来得比较突然,我已经为人父了。
最近的项目因为引入了合作方的代码,多了很多疑难问题,但这些问题也非常有意思,Debug这些问题的过程给了我很多乐趣。
这篇博客是关于一个由#pragma引起的问题,Debug过程中充满了挑战和惊喜,不停的需找线索的过程,也是一个不断提升自身水平的过程。
在某次提交代码以后,我们跑回归测试用例,出现了segmentation fault的情况。马上gdb attach上去看进程调用栈。
|
|
可以看到,第7行的赋值语句导致了SegFault,细看就能看到this指针是一个非法值0x18000000,定位到这一步以后,我们做了第一次推测,很有可能是踩内存了。
为了证明我们的推测,gdb返回上一层堆栈打印Component类的指针,结果出乎我们意料。12345(gdb) f 1#1 0x08048552 in main () at main.cpp:99 board->_com->set();(gdb) p *board$3 = {price = 0 '\000', _com = 0x804b018}
这时看到的Component类指针_com是正常的,我一度非常怀疑g++的编译器出问题了,我甚至翻阅了很多关于C++编译成员函数的资料,事实证明:一切问题都应该先从自身上找原因。
所以,我又把board的内存打印出来,看是不是有什么线索。12345(gdb) x/32xb board0x804b008: 0x00 0x00 0x00 0x00 0x18 0xb0 0x04 0x080x804b010: 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x000x804b018: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x000x804b020: 0x00 0x00 0x00 0x00 0xe1 0x0f 0x02 0x00
细心的话会发现,原本_com的指针为0x804b018,即第一行后4个字节。而this指针为0x18000000,正好是第一行从第二个字节开始的4个字节。似乎有点头绪了…
从上面的初步分析,我们基本锁定了问题的范围,在函数调用前,指针是正常的,进入函数以后指针变了。难道是函数调用出了问题?为了进一步分析,可以使用gdb的汇编调试功能,如果不熟悉的可以参考Lenky的博客。以下打印出调用set的汇编代码:123456789101112131415(gdb) disassemble mainDump of assembler code for function main(): 0x08048534 <+0>: push %ebp 0x08048535 <+1>: mov %esp,%ebp 0x08048537 <+3>: and $0xfffffff0,%esp 0x0804853a <+6>: sub $0x10,%esp 0x0804853d <+9>: call 0x804858a <Board::init()> 0x08048542 <+14>: mov 0x804a028,%eax 0x08048547 <+19>: mov 0x1(%eax),%eax 0x0804854a <+22>: mov %eax,(%esp) 0x0804854d <+25>: call 0x804855c <Component::set()>=> 0x08048552 <+30>: mov $0x0,%eax 0x08048557 <+35>: leave 0x08048558 <+36>: ret End of assembler dump.
在0x08048547行,这一行代码就是获得_com指针,前面我们看到board的偏移4个字节以后取到Component的指针,而这一行汇编代码只偏移1个字节。刹那间,4个字突然跳到我的脑海里 – 字节对齐。
我们知道在C语言里,在没有声明字节对齐的情况下,编译器会按4字节或8字节对齐。
Board类的结构如下123456789class Board{public: Board(); static void init(); char price; Component *_com;};
这里没有声明字节对齐的方式,系统是32位的,理应按4字节对齐,这个与我们看到的Board的内存是一致的。可是为什么在调用的地方,汇编代码是按1字节来偏移呢?编译器编译调用点时理解这个结构是1字节对齐,而该结构定义并没有声明1字节对齐,那肯定是别的地方影响了。结果一翻看前面几个头文件,居然有一处这样的代码:1234struct foo{};
这一出#pragma push没有对应的#pragma pop,这个头文件在Board的头文件之前,所以导致Board结构也是按1字节对齐,而由于board申请内存定义的地方没有这个问题,是按4字节对齐,所以才导致了this指针错乱的结果。
终于真相大白了,#pragma引发的血案宣布告破。
对于该编程问题的引入,我就不说什么了。对于该问题的调试,我总结出的结论是:以怀疑一切的眼光看待问题,同时要多方面去考虑问题,这样“问题”就不是什么“问题”了。
从去年12月份开始至今年年初,做了一个高性能网络处理服务器的性能优化的项目。在此简单记录
项目过程中的一些知识与方法,以备将来参考之用。
这个“高性能处理服务器”其实一点也不高性能。为什么呢,其中夹杂很多历史遗留原因。我厂的
项目存在很多“售前吹牛逼,开发很苦逼”的现象。这个产品也一样,许多年前,为了满足客户要求,
没有在性能上有过多的考虑。以致许多年后的今天,客户的要求变了,产品满足不了。
服务器处理的流程很简单:
网络收包 => 协议处理 => 分发
用程序语言来表达的话:123456while( performance != expect ) { /* 查找系统性能瓶颈 */ find(bottlenecks); /* 优化系统性能瓶颈 */ optimize(bottlenecks);}
性能优化,即在性能达不到预期时,查找性能瓶颈并进行优化,重复这一过程知道达到要求。性能瓶颈的概念
我们可以借助维基百科的定义来理解。
系统瓶颈(Bottleneck): 整个系统的性能或容量,受少数部件或资源的限制。
从软件的角度上说,资源指的是CPU、内存、磁盘、网络等;部件指的是某些模块,某些流程。
我拿到这个项目的时候,领导只是说了四个字:“性能不足”。
在我整个项目的过程,最主要的两个工具就是top和oprofile。其实如果对系统熟悉的话,只需top和量化的系统指标,
就能对系统的运行情况就能有足够的了解。再者,就是对操作系统知识的理解,如各种锁如何在cpu上体现、网络io和磁盘io在cpu上的体现、
内存的使用在什么地方等等。进一步分析时,就可以配合一些其他工具sar、vmstat等来发现问题。
谈及理论,不得不提到Brendan Gregg,以下是他写的书和Slide:
我总结出的观点是:理解“系统”,理解“系统”。
第一个系统指的是需要优化的系统软件;第二个系统指的是操作系统。Brendan的Slide就像一个理解系统软件的工具箱,
用好了这些工具就理解了第一个“系统”;Brendan的书对于我就是一本操作系统性能的知识手册,读好了这本书就理解了第二个“系统”;
前面提到发现的第一个瓶颈是某个核的CPU负荷过载了,而我们系统是运行在32核的服务器上的,其余的核远远未到满负荷。
因此,我需要做的是将过载的CPU的负荷均衡到其他CPU上。而这个均衡的方法就要结合具体业务来实施了,在我们的系统里,我们通过oprofile很快
定位到了过载的模块,再进一步分析,发现系统的处理模块居然是单线程运行的,系统的设计者肯定没有预想到scale out的情景。
此时,我们需要梳理业务的处理流程,分析出处理模块里的子模块哪些可以多线程运行,哪些是必须单线程运行的。(此处不得不提的是,对于较为完美
的scale out设计应该是各个模块都支持多线程并发运行,但由于历史遗留问题,该系统的的确确存在单点瓶颈)
第一次切分
第二次切分
经过切分过后的系统,能够将服务器上的其他核利用起来,我们可以使用set_schedaffinity来设置线程CPU的亲和力,使各线程尽量保持在同一个
CPU上运行,减少线程切换带来的消耗。
当我们将单线程切分为多线程以后,会引入线程间通信的问题。线程间的通信,经验里使用“无锁环形队列”作为桥梁是最为简单且高效的实现方式。(可以
参加http://www.github.com/wilsonwen/lockfreekit/)最理想的方式是内存零拷贝的实现方式,就是我们常说的zero copy。不过在优化过程中,发现历史
遗留的模块存在太多的自定义接口,没办法实现零拷贝,各线程交互时需要拷贝内存。这里就引入Cache优化的问题,如何部署线程才能使得内存拷贝是Cache
友好的呢?下面这张图或许能告诉我们。
为使内存拷贝尽量高效,有交互的线程要尽量放在同一个物理CPU上,这样对于L3 cache是友好的。对于scale out的同功能多线程可尽量发在同一个物理核上,
这样对L2 cache是友好的。
对于多核负载均衡,Intel有本书《Multi-Core Programming Increasing Performance through Software Multithreading》
有非常清楚的讲解。此外,在系统设计的过程中,应该尽量避免单点的出现,针对高负荷的模块
更要做好scale out的设计。
优化过程遇到过一些其他类型的性能问题:
在工作中,一直在做网络协议相关的编程,没有机会学习到更多的DB知识。
后来开始在github上混,偶然读到redis的源码,antirez写得如此简洁清晰,让我慢慢懂了些nosql db的原理。
最近,手上事情渐渐少了,闲暇之余翻翻博客,翻翻github。其中麦子迈的博客给了我很多启发,
其博客介绍了各式各样的DB系统,顿时让我觉得DB的世界真是丰富多彩。所以博客的开篇,也作为DB世界的开篇,开始一段对未知世界探索的旅程。
在此之前,翻阅过不少相关程序的源码(redis, levelDB, nessDB, rocksdb)等等。
但是认真学习过的只有redis,其代码相对较为直白。由于缺乏坚实C++基础,levelDB看的非常吃力,所以后面也要同时补全C++的知识。
学习阶段: